イントロ:生成AIカスタマイズの必要性
近年、ChatGPTをはじめとする生成AI(Generative AI)がビジネス現場でも注目を集めています。とはいえ、汎用的なAIモデルをそのまま使うだけでは、自社の業務やドメインにピッタリ合った回答や文章が得られないこともしばしばです。例えば、専門用語の多い業界向けの回答や、自社独自の文章スタイルでのコンテンツ生成など、標準モデルでは対応しきれないニーズが出てきます。そこで重要になるのが生成AIのカスタマイズです。モデルの出力をより自社仕様に近づけるために、「プロンプトチューニング」と「ファインチューニング」という2つの手法がよく使われます。本記事では、この2手法の違いや使い分けについて、初心者にもわかりやすく解説します。
用語解説:プロンプトチューニング vs ファインチューニング
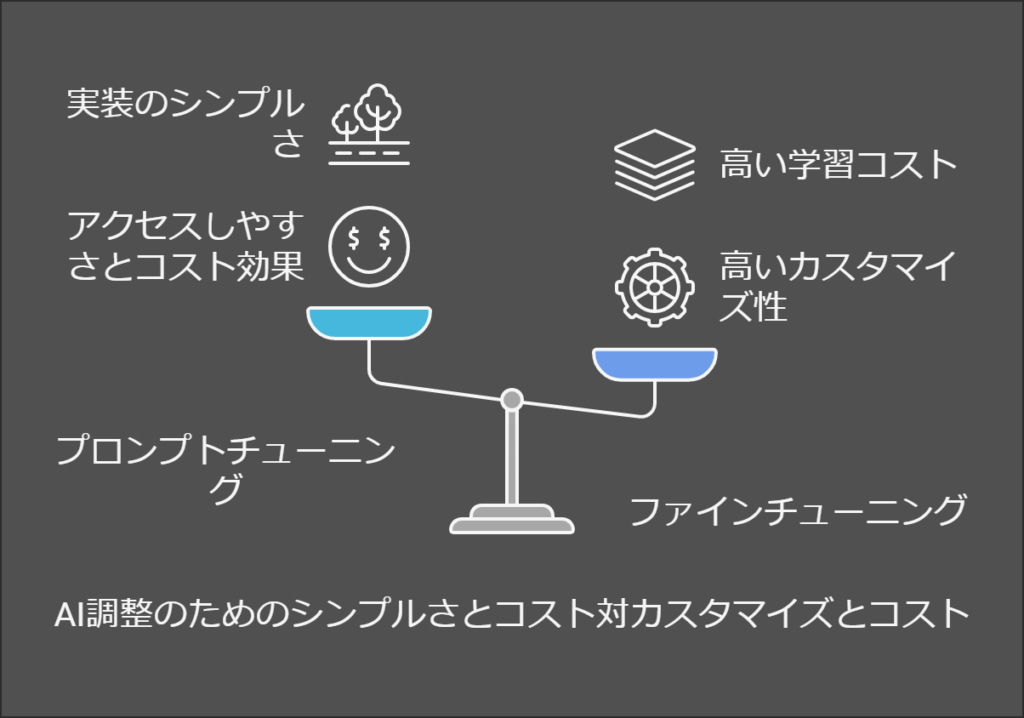
プロンプトチューニングとは、AIに与える指示(プロンプト)を工夫・調整することで、モデルから望ましい出力を引き出す手法です。追加の学習やモデル内部の変更を行わず、入力内容を最適化することで応答の質を高めます。具体的には、「システムメッセージ」や「例示(Few-Shot)」「指示の言い回し」を調整することで、モデルの振る舞いを変えることができます。その手軽さゆえ、アクセスしやすくコスト効果が高い方法ですが、モデルそのものを改変するわけではないのでカスタマイズ性は限定的です
一方、ファインチューニングとは、既存のAIモデルに追加の訓練データを与え、モデルの内部パラメータを更新(再学習)する手法です。モデル自身を調整することで、特定のタスクや文体に最適化された出力が得られます。高いカスタマイズ性を実現できますが、その分学習コスト(データと計算資源)が大きく、導入が複雑になります
要するに、プロンプトチューニングはモデルへの「指示の仕方」をチューニングするのに対し、ファインチューニングはモデルそのものをチューニングするアプローチと言えます。
ケーススタディ(業務ごとの最適な選択)
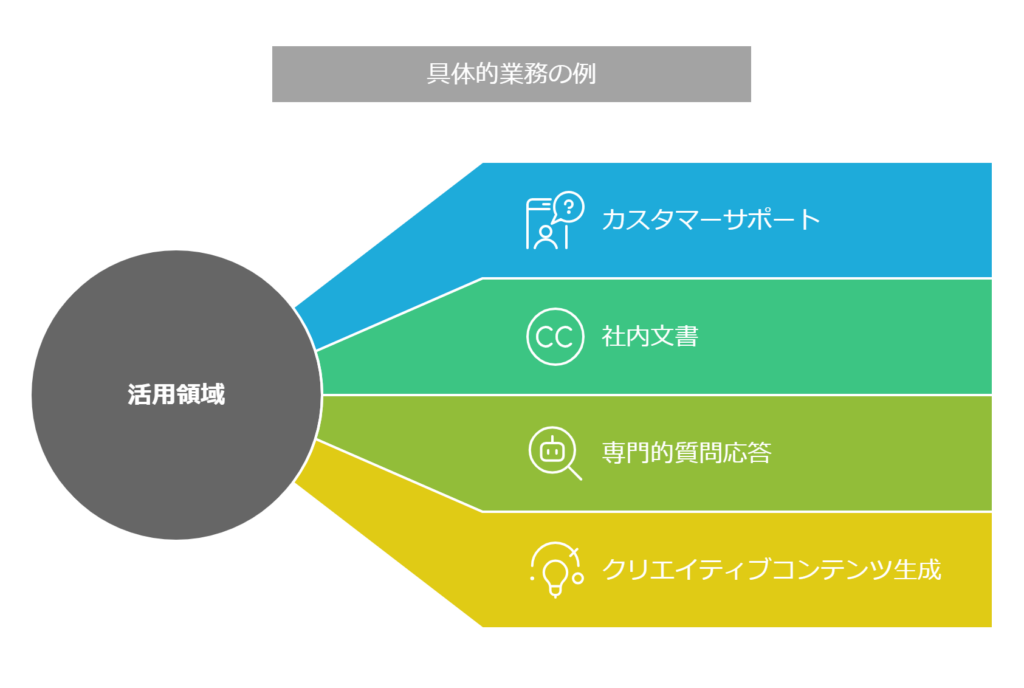
では、具体的な業務シーンごとにどちらの手法が適しているか考えてみましょう。
- カスタマーサポートのFAQ対応:社内に蓄積されたFAQデータがある場合、ファインチューニングでモデルにその情報を覚えさせることで、高精度な回答が可能になります。例えば、製品ごとの専門的な質問に対して、一貫性のある回答を自動生成できるようになるでしょう。一方、問い合わせ内容が日々変化したり最新情報を含む場合は、都度プロンプトに関連情報を与える方法(例:最新マニュアルから該当部分をプロンプトに埋め込む)が有効です。頻繁に内容更新が必要な領域では、都度プロンプトで情報を提供する方が柔軟で、安定した定型質問への対応にはファインチューニングが向いています。
- 社内文章の文体統一:レポートやメール文章を社内標準の文体・トーンに揃えたい場合、プロンプトで「○○風の口調で」など指示を与えるだけでも一定の効果があります。例えば、「ですます調で丁寧かつ簡潔に答えてください」というプロンプトを毎回付与する方法です。これは追加コストがかからず手軽ですが、毎回プロンプトを用意する手間があります。大量の社内文書データが用意できるなら、ファインチューニングでモデル自体を社内文書の文体に染めることも可能です。データが豊富で長期的にその文体を使うならファインチューニング、試行的にまずは効果を見たいならプロンプトチューニングから始めるのが良いでしょう。
- 専門分野での質問応答(例:医療・法律):高度に専門的な知識が要求される場合、ベースとなるモデルにその分野の知識を学習させるファインチューニングが効果的です。例えば、大量の医療論文データを用いてモデルをファインチューニングすれば、専門用語や知識に基づいた回答精度が上がります。実際、医療文書の要約タスクでは、医療データでファインチューニングしたモデルが正確な要約を生成できたという事例があります。逆に、学習データが用意できない場合や、モデルの汎用性(いろいろな分野の質問に一つのモデルで答えたい等)を維持したい場合は、プロンプト側で専門知識の範囲を指定したり、外部の知識ベースを参照させる方法が取られます。専門データが十分あるならファインチューニング、ない場合や汎用性重視ならプロンプトという判断になります。
- クリエイティブな文案作成:広告のキャッチコピー作成などクリエイティブ領域では、まずプロンプトで様々な案を出させ、人間が選ぶという使い方が考えられます。モデルに「○○な雰囲気のキャッチコピーを10案出して」と指示すれば、追加学習なしで多様な提案を得られます。社内に過去のコピーの蓄積があり、それらの傾向に合わせたいならファインチューニングも有効です。ただし創造性が求められる分野では、ファインチューニングしすぎると画一的な出力になる恐れもあるため、まずはプロンプトで柔軟にアイデアを出し、必要に応じて軽くチューニングする程度が良いかもしれません。
以上のように、業務内容やデータの状況によって適切な手法は異なります。ポイントは「データ量・更新頻度・求める精度」で判断することです。
比較チャート:どちらを選ぶ?
両手法の違いを改めて整理してみましょう。以下にプロンプトチューニングとファインチューニングの特徴を比較します。
| 比較項目 | プロンプトチューニング | ファインチューニング |
|---|
| 導入の手軽さ | 高い:追加学習不要ですぐ使える
(即応性がある) | 低い:データ準備や学習プロセスが必要
(時間と労力がかかる) |
| カスタマイズの深さ | 限定的:出力スタイルの調整が中心
(モデル知識自体は変わらない) | 高い:モデル内部に知識や振る舞いを埋め込める
(専門知識の付与などが可能) |
| 必要なデータ | ほぼ不要:数例のプロンプト例示で十分
(社内知見で対応可) | 多い:数百~数万件の学習データ推奨
(専門データセットが鍵) |
| コスト | 低コスト:学習用の計算資源不要
(API利用料のみ、追加費用なし) | 高コスト:学習にGPU計算やクラウド費用が発生
(データ整備や人件費も考慮) |
| 必要なスキル | プロンプト設計のスキル(非エンジニアでも可)
※AIの出力傾向を理解する力 | 機械学習エンジニアリングのスキル
※データ前処理・モデル訓練の知見 |
| 適した用途 | ・出力フォーマットや口調の微調整
・少ない試行で効果を確認したい場合 | ・専門知識や用語の組み込み
・出力の一貫性や精度を極力高めたい場合 |
| 柔軟性 | 高い:プロンプトを都度変えて様々なタスクに対応可能 | 低い:特定タスクに最適化すると他タスクには不向き |
上記をフローチャート風に捉えると、まず「十分な専用データがあるか?」で枝分かれします。データがなければファインチューニングは難しいため、プロンプトチューニング一択になります。データがある場合は、さらに「そのデータでモデルを鍛えた効果が必要か?」を考えます。例えば、多少出力にブレがあっても許容できるならプロンプトの工夫で済ませ、どうしても高精度・高一貫性が要求される場合にファインチューニングを検討するといった具合です。基本的には、最初はプロンプトで手軽に試し、限界を感じたらファインチューニングというステップを踏むのがリスクも低くおすすめです。
実践ガイド(導入のステップ)
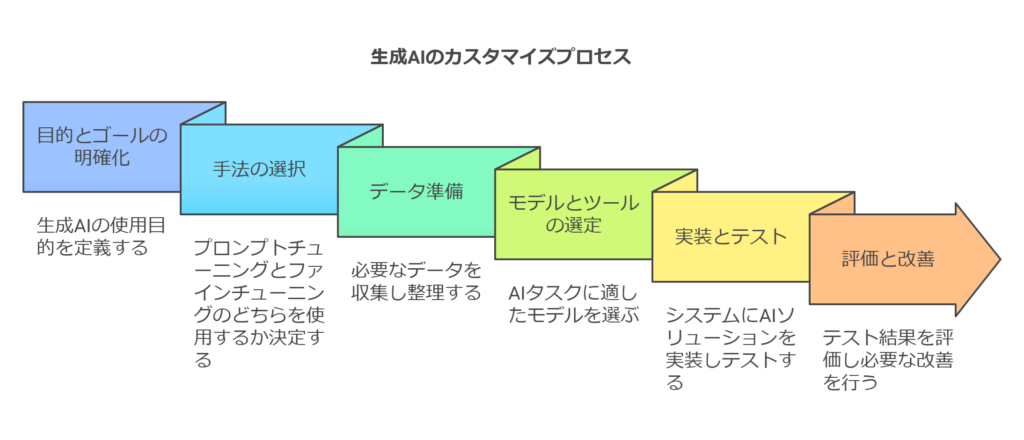
実際にプロンプトチューニングやファインチューニングを業務に導入する際の手順を、ステップごとに解説します。
- 目的とゴールの明確化: まず、生成AIを使って何を達成したいのかを定義します。回答精度の向上なのか、作業時間の削減なのか、具体的なKPI(例:回答の正解率◯%向上、作成時間◯%短縮など)を設定しましょう。
- 手法の選択: 前述の比較表やフローを参考に、プロンプトチューニングで十分か、ファインチューニングが必要かを判断します。「まずはプロンプトから試してみて、本当にモデル改変が必要になったらファインチューニングする」という段階的アプローチがおすすめです。
- データ準備: ファインチューニングを行う場合は学習データの収集と整備が必要です。過去のチャットログ、QA集、文書データなど目的に合わせてデータを用意し、フォーマットを整えます。プロンプトチューニングの場合も、望ましい出力の例示(ひな形となる回答例)があれば、それを用意しておくと効果的です。
- モデルとツールの選定: どのAIモデルをベースに使うか決めます。例えば、日本語の社内文書生成なら日本語に強いモデルを、汎用的な会話ならGPT系モデルを選ぶなど。ファインチューニングなら、自前で学習可能なオープンソースのLLMを使うか、あるいはOpenAIなどの提供するFine-tuningサービスを利用するかも検討します。プロンプトチューニングの場合は、API経由で利用するか、自社サーバーでモデルを動かすかといった運用方法も決めます。
- 実装とテスト: 選択した手法で実装に取りかかります。プロンプトチューニングなら、実際にシステムに組み込むプロンプト文を作成・調整します。ファインチューニングなら、用意したデータでモデルを追加訓練します。出来上がったプロンプトやモデルを使ってテストを行い、期待通りの出力が得られるか確認します。ここでは社内の関係者に試用してもらいフィードバックを集めることも重要です。
- 評価と改善: テスト結果を元に、改善が必要な点を洗い出します。精度が不十分なら、プロンプトの文言を修正したり、ファインチューニング用データを追加したりします。一度で完璧を目指すよりも、少しずつ調整を重ねる反復プロセスで完成度を上げていきます。
- 運用開始とモニタリング: 準備が整ったら本番環境で運用を開始します。導入後も定期的にモデルの出力をモニタリングし、想定外の回答や精度低下がないかチェックします。プロンプトであれば定期的な見直しを、ファインチューニングモデルであれば新しいデータ追加や再学習のタイミングを検討します。
以上のステップを踏むことで、小さく始めつつ効果を検証しながら、安全に生成AIのカスタマイズを導入できます。
よくあるトラブルと対策
生成AIのカスタマイズ導入時には、いくつか躓きがちなポイントがあります。ここではプロンプトチューニングとファインチューニングそれぞれで起こり得るトラブルと、その対策を紹介します。
- トラブル1: プロンプトを工夫しても期待した回答にならない
原因: モデルがそもそも持っている知識の範囲を超えている、あるいは指示が曖昧で解釈が分かれている可能性があります。
対策: プロンプト文を具体的にし、必要なら追加のコンテキスト情報を与えましょう。例えば「〇〇に関する最新の〇〇レポートを踏まえて回答してください」のように背景知識を与えると精度が上がる場合があります。また、それでも難しい場合はモデル側の限界の可能性があるため、次に述べるファインチューニングやRAG(外部データ参照)の検討も視野に入れます。
- トラブル2: プロンプトが長文化し運用が煩雑になる
原因: 要求が増えるにつれプロンプトに盛り込む指示や例が増え、結果として毎回長大なプロンプトを与えねばならなくなるケースです。コンテキストウィンドウ(モデルが一度に読めるトークン数)の上限に達し、逆に長すぎるプロンプトが原因で性能低下を招くこともあります。
対策: プロンプト内で設定できるシステム指示(モデルに対する役割指示)を活用し、一部の前提を省略する、あるいは定型のプロンプトテンプレートをシステム側で用意しておき必要な部分だけ差し替える運用にします。根本的には、あまりに複雑な指示が必要な場合はファインチューニングに切り替えた方が管理が楽になるでしょう。
- トラブル3: ファインチューニング後にモデルの汎用性が落ちた
原因: 特定のデータで訓練し直した結果、その分野には特化したものの他の分野の質問に答えづらくなったり、極端な場合はファインチューニング前にできていたことができなくなる**「忘却」が発生することがあります。
対策: まずファインチューニングのデータと元々のモデル性能のバランスを見直します。極端に専門分野のデータのみで再学習すると汎用能力とのトレードオフが大きくなります。対策として、元の汎用データも一部混ぜて学習させる(Continual Learningの手法)や、必要に応じて複数モデルを使い分ける(汎用モデルと専門モデルを用途で切り替える)方法があります。また、最近ではLoRAなどモデルの一部だけをチューニングする手法もあり、これによりベースモデルの汎用部分は維持しつつ必要部分だけ調整することも可能です。
- トラブル4: 期待したほど精度が向上しない(ファインチューニング時)
原因: 学習データが不足している、もしくはデータの質に問題がある可能性があります。また、ベースモデルの選択が適切でない場合(元のモデル性能自体が低すぎる等)も考えられます。
対策: データ量を増やせるか検討します。社内データが足りない場合、公開データで類似タスクのデータセットがないか探し、追加で学習に使うことも有効です。データのクレンジング(誤情報やノイズの除去)も忘れずに行いましょう。また、ベースモデルを変更できるなら、より性能の高いモデルや目的に近いモデルに替えて再度試すのも一手です。例えば、汎用モデルでうまくいかなければ、業界特化型に事前学習されたモデルをベースにする、といった選択肢です。さらに、学習のハイパーパラメータ(学習率やエポック数)の見直しも効果があります。精度向上はトライ&エラーになることも多いですが、一度軌道に乗れば大きな性能向上が期待できます。
- トラブル5: セキュリティ・コンプライアンス上の問題
原因: プロンプトチューニングの場合、外部のクラウドAIサービス(例:OpenAIのAPI)を使用していると、社内の機密データをプロンプトとして送信することになります。業種によってはこのデータの取り扱いが問題視されることがあります。ファインチューニングでも、クラウド上でモデル学習させる際にデータをアップロードする必要がある場合は同様です。
対策: オンプレミスでモデルを運用するか、データを匿名化・マスキングしてからAIにかけるなどの対策を講じます。機密情報を扱うシナリオでは、外部サービスを使わず自社サーバー上でオープンソースのLLMを動かすことも検討しましょう。その場合、プロンプトチューニングであっても社外にデータが出ないので安心です。ただしオンプレ運用は運用コストが上がるため、扱うデータの機密度とコストのバランスを見て判断してください。
これらのトラブルに対処することで、プロンプトチューニング/ファインチューニング導入の失敗リスクを大幅に下げることができます。特に初期段階では小さな実験から始め、問題が起きたら原因を切り分けながら対策を講じていく姿勢が大切です。
まとめ & 次のステップ
生成AIのカスタマイズ手法であるプロンプトチューニングとファインチューニングについて、その違いと使い分けのポイントを解説してきました。簡単にまとめると:
- プロンプトチューニングはお手軽で即効性があり、追加コストなくモデル出力を調整できる方法です。ただし根本的なモデル能力を変えることはできないため、できることにも限界があります。
- ファインチューニングは労力と費用がかかるものの、自社のデータやニーズにモデルを最適化できる強力な方法です。特に大量の独自データがある場合や、出力に一貫した専門性が求められる場合に有効です。
最初は誰しも手探りですが、まずプロンプト設計から始めて効果を確認し、それでも足りなければモデルをチューニングするという段階的アプローチで進めると良いでしょう。幸い、昨今はOpenAIなどでもファインチューニングサービスが提供されており、必ずしも自前で大規模なインフラを用意しなくても試せる環境が整ってきています。また、どうしても自社データを外に出せない場合にはオープン、LLMの活用(自社環境でのチューニング)も視野に入ります。
次のステップとしては、ぜひ小さなユースケースで構いませんので実際に試してみることをおすすめします。例えば社内のQ&Aボットに一工夫してプロンプトチューニングを適用してみる、あるいは社内文書の一部を使って無料で利用できる小規模モデルをファインチューニングしてみる、といった具合です。小さな成功体験を積むことで社内の理解も深まり、本格導入への道筋が見えてくるでしょう。
段階的な導入プランもご相談ください。経験豊富なエンジニアがサポートいたしますので、ご興味をお持ちの方はぜひ弊社までご連絡ください。

