目次
- イントロ:なぜオープンソースLLMが経営層の選択肢になるのか
- メリットとリスク
- 導入可否を判断するためのチェックリスト
- コスト試算(小・中・大規模別)
- 成功事例1: 国内メーカーにおける社内効率化(TOPPAN)
- 成功事例2: ブラウザ企業による製品差別化(Brave社)
- まとめ:経営層が今すぐ検討すべきポイント
なぜオープンソースLLMが経営層の選択肢になるのか
生成AIをビジネスに活用する際、経営層としては「どのモデルを使うか」「自社で構築するか外部サービスを使うか」という重要な意思決定があります。特に近年、Meta社のLlama 2に代表されるようなオープンソースの大規模言語モデル(LLM)が登場し、選択肢が広がっています。オープンソースLLMとは、ソースコードやモデル重みが公開され、自由に利用・カスタマイズ可能なAIモデルのことです。従来、最先端の生成AIといえばOpenAIやGoogleなどの提供するクラウドサービスを使うケースが多くありました。しかし、経営層にとってはデータの機密性やコストの持続性、そして他社サービスへの依存リスクといった観点で懸念が残る場合もあります。こうした中、自社で制御できるオープンソースLLMは、戦略的に魅力的な選択肢として浮上してきました。
例えば、「自社の機密データを外部に出さずAIに解析させたい」「API利用料が増大しておりコストを抑えたい」「AIを自社サービスのコアに組み込みたいがベンダーロックインは避けたい」といった経営判断ポイントにおいて、オープンソースLLMは一つの解決策を提供します。本記事では、経営層が判断しやすい視点からオープンソースLLM活用のメリットとリスクを整理し、導入可否のチェックリストやコスト・ROIの試算、さらに実際の成功例・失敗例を交えて解説します。最後に、経営陣として今すぐ検討すべきポイントもまとめます。
メリットとリスク
まず、オープンソースLLMを採用することの主なメリットとリスクを見ていきましょう。
メリット(利点)
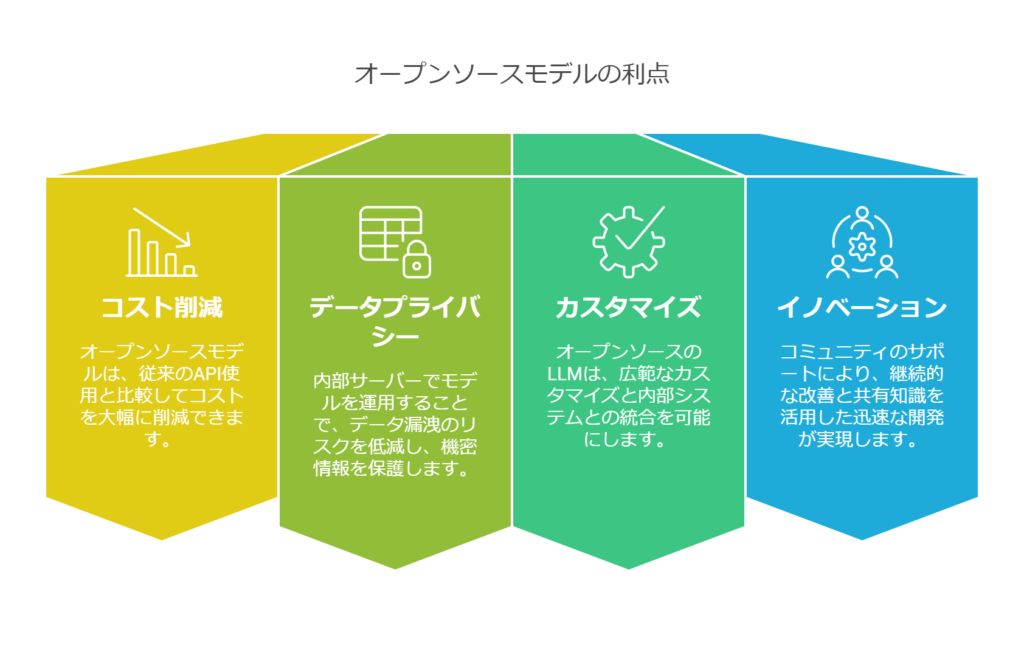
- コスト削減の可能性: オープンソースモデルそのものにはライセンス費用が基本的にかかりません(商用利用可のライセンスであれば無料で使えます)。従量課金のAPIを使い続ける場合と比べて、利用量が増えた時にコストが頭打ちにできる点は魅力です。大規模に使う企業ほど、自前運用によって長期的にはコストメリットが出る可能性があります。さらに、社内に蓄積したデータを使ってモデルを高性能化できれば、外部サービスに匹敵する性能をランニングコスト低く維持できる可能性もあります。
- データのプライバシーと所有権: 自社サーバー内でモデルを運用すれば、入力するデータや生成された結果が外部に漏洩するリスクを低減できます。機密情報や個人情報を含むデータでも社内で完結してAI解析が可能になるため、規制の厳しい業界(金融・医療など)や社外秘プロジェクトでもAI活用が検討しやすくなります。モデルに関する知的財産も自社内に蓄積されるため、ノウハウが社の資産になります。
- カスタマイズ性と柔軟性: オープンソースLLMであれば、モデルの細部に至るまでカスタマイズが可能です。必要に応じてモデルの微調整(ファインチューニング)はもちろん、場合によってはモデル構造の変更や追加機能の実装さえできます。ベンダー提供のブラックボックスなモデルでは実現できない細かなチューニングや社内システムとの密接な統合が図れます。また、モデルの選択肢も複数あります(例:Meta社Llama系列、Mistral AIのモデル、Bloomなど)、用途に応じて最適なモデルを選び組み合わせる戦略も取れます。特定のサービスに縛られず、技術の進化に合わせてモデルを乗り換える自由度も確保できます。
- イノベーションとコミュニティの活用: オープンソースの強みとして、世界中の研究者・開発者コミュニティによる継続的な改良や支援があります。最新のモデル手法や最適化ツールが公開されればすぐ取り入れられますし、不具合への対処法もコミュニティから得られることがあります。社内でゼロから開発するよりも、公開知見を活用して開発スピードを上げられるのです。結果的に、自社サービスへのAI適用において先端技術をキャッチアップし競争優位を築きやすいというメリットにつながります。
リスク(留意点)
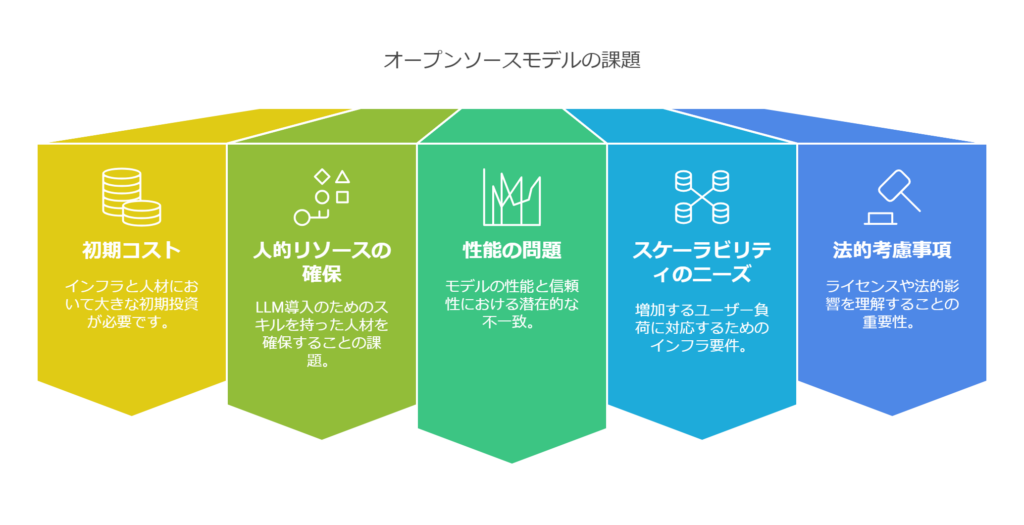
- 導入・運用の複雑さと初期コスト: 最大のハードルはここでしょう。オープンソースLLMを本番運用するには、モデルを動かすためのインフラ構築(GPUサーバー等)や、モデルを取り扱う機械学習エンジニアの確保が必要です。それらにはまとまった初期投資が伴います。特に大規模モデルになるとメモリや計算リソースの要求が大きく、クラウドを使うにしてもオンプレ環境を整えるにしても相応の費用がかかります。また、モデルを最適化してデプロイするには複数のコンポーネント(データ前処理、モデルサービング、監視など)を組み合わせる必要があり、そのオーケストレーションは複雑で高度な技術を要します。結果として、外部サービスを使えば意識しなくて良かった部分での運用上のトラブルやコスト増が発生し得ます。
- 人的リソースの確保: オープンソースLLMを扱える人材(機械学習エンジニアやデータサイエンティスト、MLOpsエンジニアなど)は市場でも限られています。社内にチームを新設する場合、採用コストや育成期間も考慮しなければなりません。外部コンサルタント等の力を借りる手もありますが、それもコスト増につながります。つまり、モデル導入だけでなくそれを支える人的体制構築が必要であり、これが不十分だとプロジェクトが立ち行かなくなるリスクがあります。極端な話、最新モデルを導入してもチューニングやメンテナンスができなければ宝の持ち腐れです。
- モデル性能と信頼性の課題: 現状で最高峰の性能を持つモデルは多くが非公開・商用のもの(例えばGPT-4など)です。オープンソースモデルは急速に進歩しているものの、特定のタスクでトップモデルに一歩劣るケースもあります。そのため、ユースケースによっては期待する精度に届かない可能性も考えておく必要があります。また、公開モデルゆえに誰でもアクセスできるため、脆弱性や偏りに関する指摘があれば世間で騒がれる可能性もあります。採用にあたってはコミュニティの評価やモデルカードの記載をよく確認し、自社の要求水準を満たせるモデルかを見極めることが重要です。
- スケーラビリティと可用性: 自社運用の場合、負荷テストやスケール対応も自前で行う必要があります。ユーザーが増えたり利用が集中した際に応答が遅くなったりダウンしたりしないよう、予め冗長構成や負荷分散を設計しておかねばなりません。オープンソースLLMを一台のサーバーに載せて運用しているだけでは、ハード障害時にサービス停止となってしまいます。可用性を高く保つには複数サーバー構成や監視アラートなどのインフラ信頼性対策も不可欠です。クラウドサービスならその辺りは向こう側で対処されていますが、自社でやるとなると見えないコストと労力がかかります。
- 法務・ライセンス面の確認: オープンソースと一口に言っても、モデルごとに利用許諾(ライセンス形態)が異なります。商用利用可能かどうか、改変や再配布の条件などを事前に法務部門と確認しておく必要があります。例えば、Metaの初代Llamaは研究目的に限定され商用利用不可でしたが、Llama 2は商用利用許諾されています。このようにモデル選定時にはライセンスの内容チェックを怠らないようにしましょう。また、万一モデルの出力によって損害が出た場合(例えば誤回答によるトラブルなど)、責任の所在が明確でないケースもあります。契約でサポートを受けられるわけではない点も頭に入れておくべきです。
以上が主なメリットとリスクです。コストやデータ制御の自由を得る代わりに、技術的・運用的責任を自社で負うことになります。経営層としてはこのトレードオフを理解した上で判断する必要があります。
導入可否を判断するためのチェックリスト
オープンソースLLM採用の是非を検討するにあたり、以下のチェックリストに沿って自社の状況を評価してみましょう。当てはまる項目が多いほど、自社での導入に前向きな土壌があると考えられます。
- ❑ 扱うデータが機密性の高いものか?
-> はいの場合:データを外部に出さずAI解析する必要があるため、オープンソースLLMを自社運用する価値が高まります(セキュリティ確保の観点)。
- ❑ 利用予定のAI機能はコア業務に深く関わるか?
-> はいの場合:外部サービス依存だと将来的な仕様変更や価格改定リスクがあります。自社のコアコンピタンスに関わる部分は自前で持つ戦略は合理的です。
- ❑ 将来的に大規模な利用が見込まれるか?
-> はいの場合:利用量が増えるとAPI費用が青天井になり得ます。一方、自社運用なら一定規模を超えるとコスト面でペイする転換点が来る可能性があります。例えば、ある試算では1日数千万単語以上を処理する規模でようやく自前運用が費用対効果に見合ってくるとされています。自社の想定規模がそれに近いなら検討価値大です。
- ❑ 社内に機械学習やMLOpsのスキルセットがあるか?
-> はいの場合:既存の人的リソースを活用できます。いいえの場合:採用やパートナー契約を検討する必要があります。人的体制はプロジェクト成功のカギですので、ここが整っていない段階で無理に始めると失敗リスクが高まります。
- ❑ AIモデルに独自のカスタマイズ要求があるか?
-> (例:自社独自の専門知識を覚えさせたい、一部機能を改変したい etc.)
はいの場合:オープンソースLLMならではの自由度が活きます。外部サービスでは実現できない独自機能を作り込めるメリットと引き換えにオープンソースを選ぶ意義があります。
- ❑ 導入までのタイムラインに余裕があるか?
-> オープンソースLLM自社導入は準備に時間がかかります。短期間で結果を出す必要があるプロジェクトには不向きです。逆に、中長期的視点で育てていく余裕があるならば、自社内能力が蓄積する分むしろメリットです。
- ❑ ベンダーロックインを避けたいか?
-> はいの場合:他社サービス依存を減らす戦略としてオープンソース活用は合致します。特に将来的にコスト交渉力を持ちたい場合、社内に代替技術を持っておくことは交渉カードにもなります。
- ❑ 現状の課題は何か?それはオープンソースLLMで解決可能か?
-> 例えば「APIの応答遅延が不満だが社内サーバーなら高速化できるかも」「生成結果の品質をもっとコントロールしたい」など具体的な課題を洗い出し、その解決策としてオープンモデル採用がマッチするか検討します。漠然とした理由(なんとなく自前でやった方が良さそう、など)ではなく、明確な課題–解決の筋道が描けるかどうかは大事です。
以上のチェックポイントを総合して判断します。一つでも「はい」があれば導入すべきというわけではありませんが、組織としての方向性・優先事項を可視化する助けになるでしょう。特に人的リソースとセキュリティ要件は天秤にかけにくい要素なので、経営判断として重みづけしておくことをおすすめします。
コスト試算(小・中・大規模別)
次に、実際にオープンソースLLMを導入した場合のコスト感について、小規模・中規模・大規模の3パターンで考えてみます。ここで言うコストには、ハードウェアやクラウド費用に加え、人件費なども含めた概算とします。
小規模導入の場合
想定: 部署内や小チームでの試験導入。ユーザー数は数十人以下、問い合わせや生成の頻度も1日あたり数百~数千トークン程度と限定的。
インフラ: オープンソースLLMの中でも小型のもの(例えば7億~13億パラメータ級のモデル)を使用し、GPU1台で処理する構成を考えます。クラウドでNVIDIAのT4やA10G程度のGPUインスタンスをオンデマンド利用すれば月額数万円程度から始められます。オンプレの場合でもワークステーション級PCに比較的安価なGPUカード(数十万円)を積めば動かせる規模です。
運用: エンジニア1人が他業務と兼任しつつ細々と面倒を見る程度で回るでしょう。場合によっては、社内の有志が検証目的で進める段階かもしれません。
費用感: ハード費用で数十万円(クラウドなら利用期間分の従量課金)、人件費は専任0.1人月分程度とすれば、ざっくり年間100~200万円以内に収まるイメージです。ただし、クラウド利用料は使い方によって増減が大きい点に留意してください。なお、小規模であれば外部のAPIを使ってもコストはさほど高くならないケースが多いです。比較として、OpenAIのGPT-4を月間で数十万トークン利用しても数万円程度ですので、「まずは外部APIで試し、後からオープンソース移行を検討する」という段階的アプローチも十分考えられます。
中規模導入の場合
想定: 社内の複数部署で利用、または社内向けサービスとして社員全員(数百~千人規模)が日常的に使うケース。1日の利用は数万~数十万トークン程度。
インフラ: 性能と安定性を考慮し、ミドルクラスのモデル(20~30億パラメータ級や場合によっては65億規模)を使用。推論用GPUを2~4台ほど用意し、ロードバランサで振り分ける構成などが考えられます。クラウドの場合、AWSやAzureでGPUインスタンスを常時起動するとそれだけで月数十万円以上になります。オンプレで専用サーバーを用意するなら、GPUサーバー(例えばA100 40GB ×4枚搭載など)を購入して数千万円といった初期投資も視野に入ります。
運用: MLOpsエンジニアやインフラ担当を含むチーム体制が必要です。少なくとも数名はこのプロジェクトにコミットする形になるでしょう。モデルの監視や定期的な更新作業も発生します。
費用感: 初期投資として数百万円~数千万円(オンプレ機材の場合)、クラウドでもPoCから本番まで継続すれば年間で同程度の費用感になります。加えてエンジニア数名分の人件費(年間で数千万円規模)が乗ってきます。例えば年額2000~5000万円程度は見込んでおくイメージです。このレベルになると、それなりのコストではありますが、同規模感で外部サービス(API)を大量利用した場合のコストと比較検討が必要です。利用量次第では、年間数千万のAPIコストが発生するケースも十分ありえます。したがって、中規模以上になると単純に「自前=高い、外部=安い」とは言えなくなり、細かなシミュレーションが重要になります。
大規模導入の場合
想定: 自社プロダクトへの生成AI組み込みや、大企業全社で社内AIアシスタントを展開するケース。ユーザーが数万人~、トークン消費が日億単位に及ぶ可能性もある大規模シナリオです。
インフラ: 高性能なモデル(70億~数百億パラメータ)を前提とし、推論用GPUも多数台必要です。データセンターに専用のAIクラスタを構築する、もしくはクラウドの大規模GPUクラスターを契約するといったレベルになります。可用性とスケーラビリティのためにリージョン冗長構成やコンテナオーケストレーション(Kubernetes等)を駆使して、自動スケールやフェイルオーバーも備えるでしょう。初期構築に数億円単位の投資、月々の運用費用も数百万円~という世界です。ただし、このクラスになると外部APIを同等規模で使った場合の費用も極めて高額になります。例えばGPT-4を数千万~億単位のトークン/月で利用すれば、それだけで数千万円規模の請求が来る可能性があります。
運用: 社内にAI開発部門を持つレベルで、人員も10人以上が関与するプロジェクトとなるでしょう。モデルの継続的な評価・改良、追加トレーニング(例えば定期的な再学習や追加データでのチューニング)なども織り込んだ運用になります。
費用感: 年間1億円以上を見込んだ投資になります。大企業にとって数億円のIT投資は決して小さくないですが、他方でそれによって得られる業務効率化・新規ビジネス創出のリターンがそれを上回るかどうかがポイントです。仮に社内事務作業を横断的に50%自動化できるなら、その人件費削減効果だけで元が取れるかもしれません。この規模では、ROI試算をしっかり行い、経営判断として投資に見合うだけの価値があると裏付けることが必要です。
以上、規模別にコスト感を述べましたが、重要なのは比較の軸です。単に「自社運用は高い」ではなく、「同じ要件を外部サービスで満たす場合と比べてどうか」「投資対効果はあるか」を総合的に判断することになります。例えば、前述のある分析では自前運用の年間コストは最低でも6.5万ドル(約700万円)程度かかり、人件費等含めると20万ドル(約2500万円)を超えるとも言われています。一方で、それだけコストをかければ、API利用で処理できるトークン数は莫大になります。つまり、多くのケースで「よほど大量に使う」かつ「データを手元に置きたい」場合にのみ自前のメリットが際立つというのが実情です。この辺りを踏まえ、次章では実際の成功例・失敗例を見てみましょう。
成功事例
実際にオープンソースLLMを取り入れた企業の事例をいくつか紹介します。その成果と課題から、現実的な期待値を掴んでいただければと思います。
成功事例1: 国内メーカーにおける社内効率化(TOPPAN)
大手印刷会社の凸版印刷(TOPPAN)は、社内システム開発業務に生成AIを導入し、オープンソースのLLMを自社サーバー上で運用しました。その結果、プログラマーが行う社内システム向けプログラム開発の作業時間が最大70%短縮される効果を確認しています。このプロジェクトでは、OSS-LLM(オープンソースの大規模言語モデル)を用いて高度にセキュアな社内環境でAIを稼働させ、さらに特定業務に特化した形でモデルを調整しています。特化することで学習量を抑えつつ頻繁な情報アップデートを可能にし、常に最新の知見を反映できる仕組みを構築しました。この事例のポイントは、機密性の高い環境でAIを活用しつつ、限定的な領域にフォーカスすることで大きなROIを実現したことです。経営層から見れば、明確な業務効率化(70%時間短縮)という数字が出ていますので、初期投資に対するリターンが説得力を持って示された成功例と言えます。
成功事例2: ブラウザ企業による製品差別化(Brave社)
プライバシー重視を掲げるブラウザ開発企業のBraveは、自社ブラウザに組み込むAIアシスタント「Leo」において、オープンソースLLMを活用しています。もともとMetaのLlama 2を利用していましたが、モデルの性能向上のためMistral AI社のオープンソースモデル(Mistral 8×7B)へ切り替えたと発表しています。小型のモデルを組み合わせることで動作の軽快さと応答性能を高め、ブラウザネイティブにAI機能を提供するという差別化を実現しました。Brave社にとっては、外部APIに頼らずオープンモデルを組み込むことでユーザーデータのプライバシーを守りながらAI機能を提供できた点がメリットです。また、新しい優秀なモデルが登場すれば自社判断で速やかに採用できるため、ベンダーに縛られず機能改善のスピードを保てる利点もあります。このように、自社プロダクトに深く組み込むAIにはオープンソースが適している例と言えます。
まとめ:経営層が今すぐ検討すべきポイント
最後に、経営層の皆様がオープンソースLLM活用について今すぐ検討すべきポイントをまとめます。
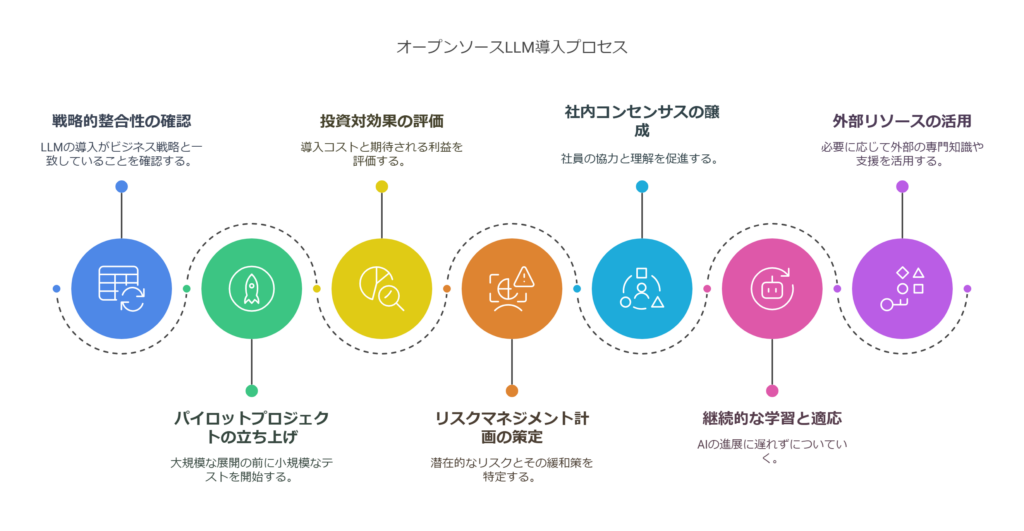
- 自社の戦略との整合性確認: オープンソースLLMの導入が、自社のビジネス戦略・IT戦略と合致しているかを検討してください。長期的にデータ資産を社内に蓄積しAIを差別化要素にしたいのか、それとも当面は外部サービスでスピード重視か。経営方針としてどちらを優先するか明確にしましょう。
- パイロットプロジェクトの立ち上げ: いきなり大規模導入ではなく、小さなパイロットから始める計画を立てることをお勧めします。前述のチェックリストで「はい」が多かった場合でも、まずは限定範囲で試験導入し、社内の技術スタックやワークフローに組み込めるか確認しましょう。パイロットの結果は経営判断の貴重な材料になります。
- 投資対効果(ROI)の試算と目標設定: 導入にかかるコストと期待効果を数値化し、意思決定の指標を設定します。「年間◯◯万円のコスト増に対し、業務効率化で◯◯万円相当の工数削減」など、できるだけ定量的な根拠を用意しましょう。ROIが不透明なまま進めると、後々プロジェクト継続の是非判断が難しくなります。
- リスクマネジメント計画: 技術的な失敗リスク、スケジュール遅延リスク、そしてセキュリティリスクなど、考えられるリスクとその対応策を洗い出しておきます。例えば、「精度が出なかった場合は外部サービス併用に切り替える」「主要メンバーが不足したら専門企業に支援を求める」「モデルの出力検閲プロセスを設け法的リスクに備える」といったプランBを用意します。経営陣がリスクを正しく認識し管理することで、現場も安心して挑戦できます。
- 社内コンセンサスと文化醸成: AI導入には現場の協力も不可欠です。経営層から現場へのコミュニケーションとして、なぜオープンソースLLMに取り組むのか、そのビジョンを伝えましょう。トップダウンの決定でも、メンバーがメリットを理解し主体的に動いてくれる環境を作ることが成功の鍵です。「社内の誰もが安全に使えるAIを提供する」「業務負荷を減らし創造的な仕事に時間を使ってもらう」といった前向きなメッセージを共有してください。
- 情報収集とアップデート: 経営層自身も最新のAI動向にアンテナを張り続ける必要があります。AI技術は3ヶ月先でも様変わりする速さです。定期的にレポートを受け取る、カンファレンスに参加する、専門家と意見交換するなどして、常に意思決定に必要な情報をアップデートしてください。特にオープンソース界隈は日々新しいモデル・手法が出ていますので、「昨日の常識が今日は非常識」ということも起こり得ます。
- 外部リソースの活用検討: 社内だけで賄おうとせず、必要に応じて外部企業やコミュニティを活用することも検討しましょう。最近では、オープンソースLLMの導入支援を専門とするスタートアップも出てきています。彼らのプラットフォームを使えば、モデル訓練からデプロイまでワンストップで行えるため、自社で一から構築するより迅速かつ確実に成果を出せる場合があります。費用対効果次第ではアウトソースや提携も視野に入れてください。
オープンソースLLMの導入に興味があるものの「どこから始めればいいのかわからない」「自社に導入した場合のコストと効果を知りたい」といったご相談がございましたら、ぜひ当社にお問い合わせください。

